fraud_data
Fraud Data Analysis
Yazar: Mustafa Eroğlu
Tarih: 8 Haziran 2022
Bu projede Amerika'daki firmaların muhasabe verileri içeren fınal veri seti ile çalıştım. KMeans,Pytorch ve VarianceThreshold kullanarak analiz yaptım.
Veri setini görelim
fraud_data
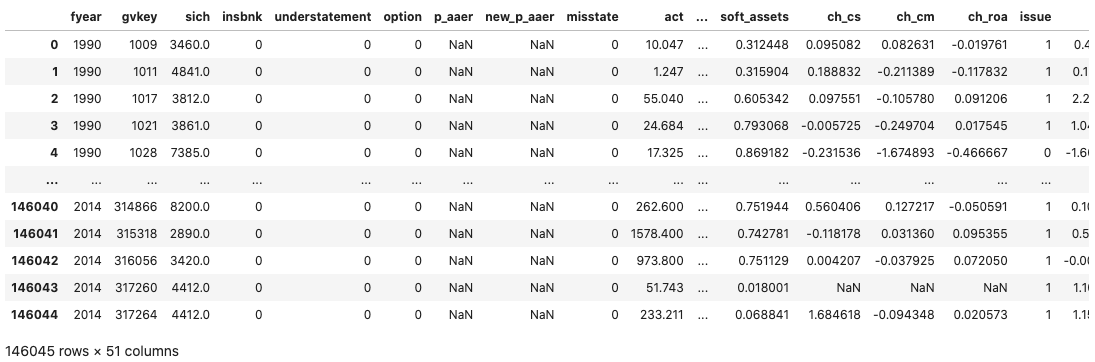
fraud_data null değer içerdiği temizliyoruz.
cleaned_fraud_data = fraud_data.dropna(axis=1)
cleaned_fraud_data
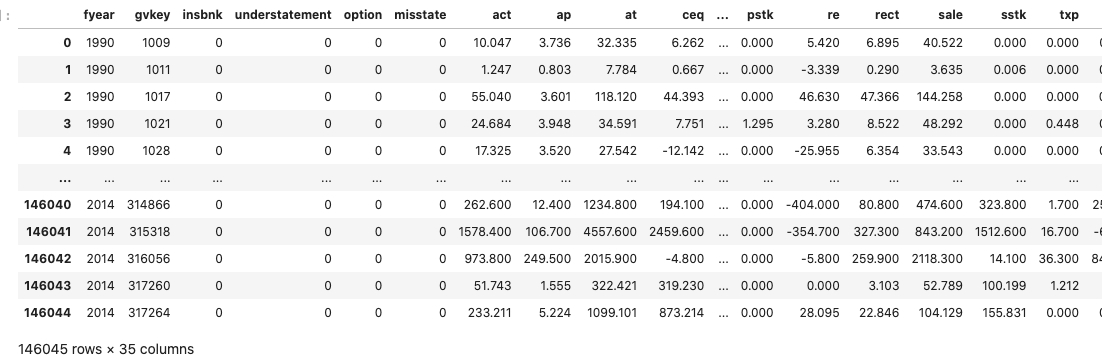
Temizlediğimiz verinin saçılım grafiğini çizdirelim.
plt.figure(figsize = (12, 9))
plt.scatter(cleaned_ap, cleaned_sale)
plt.xlabel('ap')
plt.ylabel('sale')
plt.title('Visualization of data')
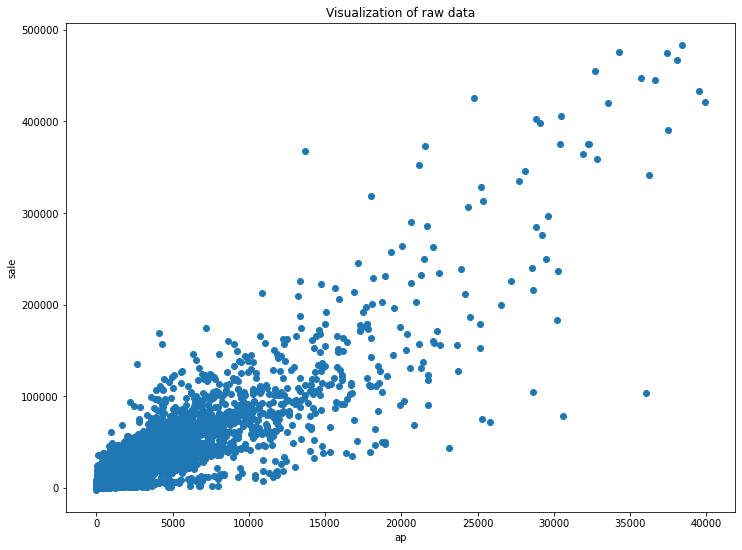
StandardScaler ve KMeans algoritmasını uyguyalım.
Verinin saçılım grafiğini çizdirelim.
plt.figure(figsize=(10,8))
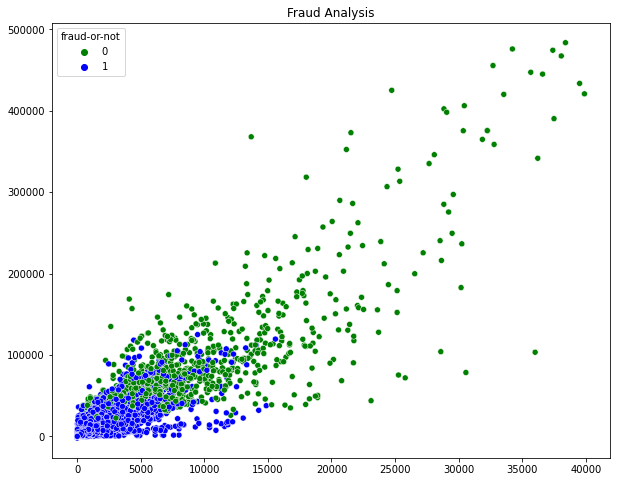
sns.scatterplot(cleaned_ap,cleaned_sale,hue=df_fraud_label['fraud-or-not'],palette=['g','b'])
plt.title('Fraud Analysis')
plt.show()
Silhouette skorunu hesaplayalım.
from sklearn.metrics import silhouette_score
score = silhouette_score(df_cleaned,kmeans.labels_,metric='euclidean')
#Print the score
print('Silhoutte Score: %.3f'%score)
Silhoutte Score: 0.918
Temizlediğimiz veriyi tekrardan gözden geçirelim.
cleaned_fraud_data.head()

cleaned_fraud_data.shape
(146045, 35)
VarianceThreshold algoritmasıyla düşük varyanslı featureları silelim.
Bu işlem sonucu np array döner. var_thres_clean değişkenine atayalım.
var_thres_clean = sel.fit_transform(X)
var_thres_clean
Bu işlemden sonra kalan featureların indislerine bakalım.
features = sel.get_support(indices=True)
features

var_thres_clean'i DataFrame'e dönüştürelim.
variance_cleaned = pd.DataFrame(data=var_thres_clean,columns=cleaned_fraud_data.iloc[:,features].columns)
variance_cleaned.head()

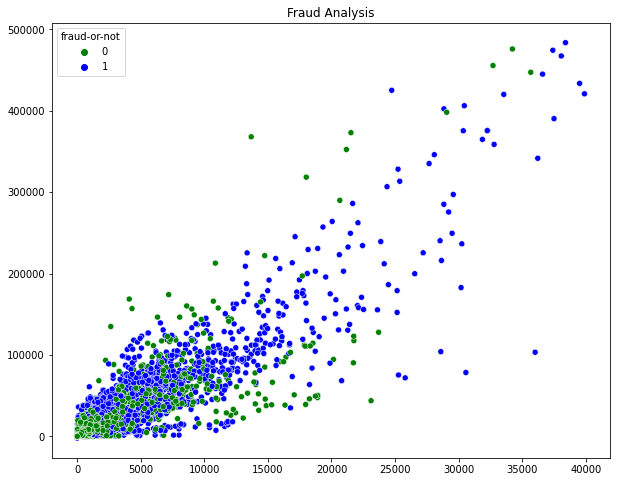
KMeans algoritmasını uygulayıp ve label verdikten sonra saçılım grafiğini çizdirelim.
plt.figure(figsize=(10,8))
sns.scatterplot(variance_cleaned_labeled_ap,variance_cleaned_labeled_sale,hue=variance_cleaned_labeled['fraud-or-not'],palette=['g','b'])
plt.title('Fraud Analysis')
plt.show()
Silhoutte skorunu hesaplayalım.</p ``` #silhouette_score ``` ``` from sklearn.metrics import silhouette_score score = silhouette_score(var_thres_clean,kmeans.labels_,metric='euclidean') #Print the score print('Silhoutte Score: %.3f'%score) ```
Silhoutte Score: 0.750
PyTorch'u kuralım.
``` import torch import numpy as np !pip install kmeans_pytorch ``` PyTorch KMeans kullanımı:
``` from kmeans_pytorch import kmeans torch_var_thres_clean = torch.from_numpy(var_thres_clean) cluster_ids_x, cluster_centers = kmeans( X=torch_var_thres_clean, num_clusters=2, distance='euclidean' ) ```running k-means on cpu..
[running kmeans]: 3it [00:00, 6.36it/s, center_shift=0.000000, iteration=3, tol=0.000100]
Silhoutte skoru hesaplayalım.
``` from sklearn.metrics import silhouette_score score = silhouette_score(var_thres_clean,cluster_ids_x,metric='euclidean') #Print the score print('Silhoutte Score: %.3f'%score) ```Silhoutte Score: 0.750
Okuduğunuz için teşekkürler